Abstract i
Executive
Summary. ii
Introduction. 2
An
Enterprise Data Strategy Improves the Way an Enterprise Leverages Its Data. 2
Storage
Networking Has Become a Necessity. 3
Data
Warehousing Adds Value To a Repository. 3
Knowledge
Management Finally Means Something. 4
Enterprise
Data Must Be Defined and Verified. 6
Structured
Data. 6
Unstructured
Data. 7
· Metadata. 7
· Semantic File Systems. 8
· An example: Cypress Content
Integration Software. 9
Conclusion. 10
References. 11
The burst
bubbles of dot-com and high-tech investment have left CIO’s wondering which
technology investments are truly worthwhile. COO’s wonder how to further
improve business processes, given the information they
have about the way their business operates. CEO’s wonder which ideas they can
trust to change their organization for the better. The answers for all these
professionals very likely already exist within their organization’s data. The
key to reaching those answers is created with the integration of the
organization’s data into an easily accessible and comprehensive repository.
Queries into the repository must return intelligent knowledge that can enable
decision making and produce results.
The
greatest challenge during the integration of enterprise data is the inclusion
of unstructured data contained in various file types, such as text documents,
presentations, spreadsheets, graphics, and scanned items. Integrating all of
the data found in these file types is an arduous task that is simplified if the
enterprise has an infrastructure in place to execute it. My paper will briefly
mention the elements of such an infrastructure, and then describe methods of
comprehensively representing data for enterprise decision makers.
[Back to
Table of Contents]
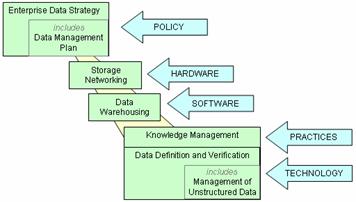
An Enterprise Data Strategy Improves the Way an Enterprise Leverages Its Data
Prior to
the implementation of technological solutions to solve informational issues, an
enterprise must first determine how it wants to manage its data. It must
develop a strategy that includes four components: enterprise data architecture,
analytic capabilities, an action plan, and data management. The data architecture
refers to the physical and logical structure that contains the data and
delivers it to the user. Required analytic capabilities are determined by
answering the question, “What shall employees, business partners, and customers
achieve when they are presented with requested data?” The action plan allows
the enterprise to migrate from their current situation to one that incorporates
the other goals without disrupting productivity. Data management refers to the
systems and policies that make data useful (Mullen). The most useful data have
been integrated into one universally accessible system that includes structured
and unstructured data. The storage, consolidation, incorporation, and
integration of unstructured data are described in detail within this paper.
[Back to Table of Contents]
Storage Networking Has Become a
Necessity
Data
integration cannot be accomplished when files are stored at each computer’s
hard drives. This storage method, known as Direct Attached Storage (DAS),
unnecessarily complicates access to files on other computers. Integrating data
requires collecting and storing files in a common location that all users on
the network can reach. Devices made solely for this purpose are Network
Attached Storage (NAS). A NAS device typically contains a RAID array, a specialized
operating system, and an interface card. All applications and users requiring
access to the files do so indirectly, through a client-side interface (Ortegon, 2001).
One
currently vogue feature of NAS is virtualization. This is a way of representing
storage structure to the user other than by storage location (such as drive,
server, or device). Virtualization allows files to be physically maintained
wherever necessary, but pools them together at the interface (Virtualization,
2000).
A Storage
Area Network (SAN) is a worthwhile asset when data is structured and can be
accessed by block rather than by file. A SAN is the infrastructure of
interfaces, cables, switches, and protocols that typically transfer data from
storage devices to servers. One example is a Fiber Channel infrastructure
between database servers and a RAID array. The servers each run an operating
system and application, but all of them store and access data at an external
device via the SAN. SAN’s are in favor because of
their very high data transfer rate, versatility, and expandability (Ferrarini, 2002).
[Back to
Table of Contents]
A data
warehouse is a common repository of organizational data. It is most easily
housed in NAS and/or accessed via a SAN. A data warehouse adds value to simple
physical storage networking by providing a logical structure to the data. A
common implementation sweeps enterprise transaction data into the warehouse
daily. This shifts a large amount of an organization’s storage capacity
requirement from the transaction servers to the data warehouse.
More
important than acting as a simple repository for data, a data warehouse must
allow users to intelligently use the data. At a minimum, it must enable report
generation. Additional data warehouse services include data cleansing and
staging. These are processor-intensive tasks that attempt to “make sense” of
the massive amounts of incoming data. The software responsible for these tasks
converts, analyzes, and routes data into the logical structure. Ideally, the
warehouse processes data and transforms it into meaningful views for analysis.
The best data warehouses are flexible to change with the organization. Those
that allow customized data queries can adapt to changing business goals. Also,
allowing various methods of data input keeps the data warehouse relevant if the
organization grows or shifts through acquisitions and mergers or office moves (Goolsby, 2001).
The
preferred access point to a data warehouse is via a portal, such as an Intranet
home page. The portal is the entry point for all users. However, it must offer
a range of methods to access data, based on the category of user.
Common
user categories include executives, analysts, knowledge workers, and front line
workers. A data warehouse must address their differing data use requirements.
Executives prefer seeing predefined reports or accessing an executive
information system that filters data relevant to their responsibilities.
Analysts use tools to create advanced queries and reports, as well as conduct
what-if analysis and on-line analytical processing. Knowledge workers require
simple queries and report writing tools. Front line workers can benefit from
pre-defined data queries, reports, and views. Tailoring a customizable portal
ensures that each user gets the greatest benefit and most efficient access to
all data.
By
allowing users to access all applicable organizational data, a data warehouse
can simplify the definition and achievement of business objectives. It is a
business investment, rather than simply a technology initiative. Proven results
have been realized within financial, marketing, and sales areas, as well as
production. Nevertheless, the costs and efforts of this type of project demand
a long-term commitment from executive sponsors (van den Hoven,
2002).
[Back to
Table of Contents]
The term
Knowledge Management (KM) was introduced to Information Technology in the
1980’s, and suffered a long period of abuse during the following decades. It
was applied to Artificial Intelligence, access portals, and search engines.
With recent developments in web browsers and data warehousing, KM has found a
unique definition: it includes the uniform interface, services, and
applications that allow universal access and analysis of documents, messages,
and other unstructured data sources using criteria defined and managed by the
enterprise.
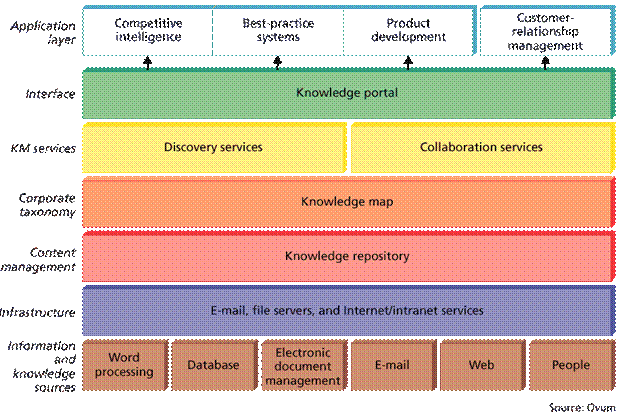
Layers within Knowledge Management (Lawton, 2001)
Structured
data is the "what" of the organization: records stored in fields of
databases, controlled by database management systems. Unstructured data is the
"why": files containing text, photographs, diagrams, sounds, or other
media in other formats not suitable for strictly-defined fields of a structured
system. Knowledge Management that incorporates unstructured data greatly
increases the data warehouse's value to the user. While data warehouses have
traditionally been built to hold structured data, methods are emerging to
incorporate unstructured data into data warehouses. A first step in organizing these
data types is controlling user and application access to the data, achieved
through the use of Knowledge Management systems. Once such controls are in
place, the data can be cataloged within a structured data system. This gives
the users all the benefits of a data warehouse while creating, seeking,
modifying, or querying unstructured data.
Knowledge
Management is not implemented simply by purchasing and installing a
technological tool. KM’s usefulness to an organization is heavily dependant
upon the methodology employed. This relies on the types of information found
within the enterprise’s files, as well as the ways in which users can apply the
knowledge they access. The Knowledge Manager must focus on managing knowledge
as opposed to simply managing documents or systems. Data sources added to a KM
system must address and be relevant to strategic priorities. Once the
organization has determined what to include and how to utilize this resource,
it can begin to research technological solutions to meet its needs.
Though 80%
of all large corporations are studying or implementing some form of KM, no
standards are in place yet. All solutions are proprietary and unique, thus
leaving the market fragmented. Nevertheless, even without standards, KM has
developed greatly from its early days. Initially, universal access to
unstructured data depended heavily of Boolean searches through the texts of
each document. The latest KM technologies employ semantic-processing engines
and other complex tools to parse, define, and index file contents (Lawton, 2001).
[Back to
Table of Contents]
Enterprise Data Must Be Defined and Verified
Structured
data that will populate a KM system must be identifiable by its content and value,
then logically stored accordingly. The first step in doing so is defining the
type of data present. Delos Technology, a supplier of enterprise data usage
solutions, divides data into three categories: Reference, Transactional, and
Derived.
Reference
data describes items, such as customers. These data are highly volatile and
require continual maintenance. Transactional data includes records of
activities that have occurred, as well as identifiers linking them to
references. Such data are not likely to change. Derived data are created by the
organization via mathematical or logical functions applied to other data (e.g.,
income) to create a new set of related data (e.g., payable taxes).
The
Reference data type is the root of the other forms. It is therefore essential
to aggregate this type of data to avoid discrepancies in copies. During the
course of the aggregation, the reliability of collected data must be taken into
account. An indicator of reliability is the number of redundant sources
providing identical data. Delos Technologies believes in maintaining multiple
sources for Reference Data within an enterprise Operational Reference Store
(ORS). This is an extension of the traditional concept of an Operational Data
Store (ODS). The ODS segregates currently applicable transactional records from
warehoused data and open records. The ORS, on the other hand, is data
aggregated from various applications that add elements to reference data. Data
cleansing, standardizing, and formatting are added value components of the ORS
(Skeogh, 2002).
The usage
of unstructured (file) data within an integrated system can be achieved through
two ways: accessing file information about the data, or directly accessing the
data. Tasks such as browsing, indexing, cataloging, and querying are achieved
more quickly and easily if the source file data does not need to be accessed
directly. Two utilities for indirect access are metadata and semantic file
systems. Direct access provides immediate exposure to the full content of the
files, but is usually only possible after all the content has first been
converted to a standard format. One such conversion service is provided by software
from a company named Cypress.
Metadata
give users and knowledge management systems a description of file contents. The
knowledge of file contents via metadata relies on the collection of information
about each file’s contents. The collected information can be stored within the
file as internal pointers. This is the same way that other definitional file information,
such as file name and date, is stored. The utility of metadata depends on the
file type and usage.
Sometimes
it is important to define relationships within or between files. These
inter-data relationships can be defined with static references, such as for
hypertext and workflow systems. Dynamic references add functionality for files
involved in change management. Changes
in the dynamic references could, for example, trigger alarms to create
notifications of the change elsewhere in the integrated system.
Applications
and operating systems use environmental information about the state of open
files, such as permissions, licensing, and user information. Compilers generate
information about program data types that is used at compile-time. Run-time metadata
is used by these applications and compilers to enhance their relationship with
the files they use.
Data
Models are external representations of files, such as database management
systems and registries. These stores maintain information about data structures
and attributes such as data types, indices, inter-file relationships, and
interfaces.
The data
content of multimedia files must usually be transcribed into metadata manually.
Such files include images, videos, and music. No standard structure exists for
such files. Therefore, metadata are required to provide associative information.
Manual entry of metadata may be based on keywords and may also be associated
with other multimedia data and textual data through relationships.
Use of
metadata to index unstructured data requires a metadata management strategy.
Management can mean a new interface that readily provides the metadata to the
user. The interface can work as a gateway to draw together metadata from
systems that interoperate. The interface operates atop a rules set that
identifies, categorizes, and correlates metadata. Alternatively, the interface
can be connected to a back-end system that actually fuses the metadata into one
repository. When fusion uses mediation code to organize values and categorize
virtual objects, the metadata management system becomes more of a semantic
gateway (Seligman, 1996).
Understanding
the meaning, or semantics, of file content has traditionally been a human task.
However, there is a growing need for querying file content based on semantics.
This has led to the development of semantic file systems. These systems add
accessibility to files by merging an integrated view of data into the file
system.
File
semantics can be divided into five categories of file information. Definitional
information may identify the file type and associated applications, such as a
file name extension does. Associative information may be provided by keywords
that begin to describe the file content. Structural information describes the
physical and logical structure of the file, as well as inter-file
relationships. Behavioral information gives viewing and modification
instructions or properties, and may also be used by change management systems.
Finally, environmental information simply includes attributes such as author,
permissions, and revision history.
Current
popular file systems used by operating systems such as UNIX and Microsoft only
provide some definitional and environmental information about their files. The
Apple File System contains a great potential for file system semantics that is
rarely fully utilized. Many Apple files contain a data fork and a resource
fork. The resource fork can hold a large amount of definitional and
environmental information, but can sometimes also hold other information types.
However, the internal definition of each file's resource fork is
application specific and usually proprietary. The lack of a standard often
dissuades knowledge managers from
fully implementing the utility of the resource fork. Integrators need uniform access to standardize information about
their files, and require a solution that integrates more file data.
When
applying a Semantic File System, data integrators want to match or exceed the
capabilities they have to query, access, and manipulate structured data. They would like to integrate interfaces,
queries, references, and transactions. An integrated interface provides one
type of view to all file folders, as virtualization does, regardless of the
files’ physical location or the folders’ structure. Query Integration relies on
the federation of databases and the file system to understand and process
queries uniformly and produce a seamless result. Allowing objects and
components of files and databases to reference each other’s components without
limits achieves Reference Integration. Integrating transactions means
preserving the atomicity, consistency, isolation, and durability of data when
files within KM systems are manipulated (this is traditionally only required of
database systems) (Georgalas, 1998).
·
An example: Cypress Content Integration Software
Docusuite
from Cypress Corporation is an example of Knowledge Management software that purports
to integrate structured and unstructured data across an enterprise. The central
purpose of this software is to enable an enterprise to distill information via
direct access to files in its data repository to generate concise output
products. The application package integrates
and queries content from multiple platforms (mainframes, minis, and PCs) and
controls multiple print spoolers. The result is a uniformly presented data
package that is printable in a proprietary format. The terms “spooling” and
“printing” are applied metaphorically to refer to the addition of files to the
DocuVault, Cypress’ proprietary knowledgebase. The terms are also applied to the
output of knowledgebase queries, to several destinations, including paper
printers, the web, e-mail applications, fax machines, or other applications
defined by the user. Files that are incorporated (“printed”) into the DocuVault
retain their original metadata, and can also gain any additional metadata that
the user has automated or manually included (Cypress, 1999).
[Back to
Table of Contents]
The
integration of enterprise data is a key project in systems integration. The
first step of such a project is the development of a
Enterprise Data Strategy. Part of that strategy is a Data Management plan. Best
practices dictate that such a plan considers Storage Networking. Once the
physical storage infrastructure is implemented, Data Warehouse software collects
and begins to make sense of a organization’s complete
data resources. Comprehensively fulfilling the goals of a data integration
project requires the inclusion of both structured and unstructured data. This
typically requires some form of Knowledge Management (KM). KM can use a variety
of tools, such as managed metadata or semantic file systems, to give structure
to unstructured data. One example of such KM software is DocuSuite from Cypress
Corporation. Sequentially implementing these processes, practices, and systems will
enable more intuitive access and intelligent use of an enterprise’s
unstructured data within an adequately supportive environment.
[Back to
Table of Contents]
Cypress Corporation (December 4, 1999). The Value of Content.
Retrieved April 28, 2002, from http://www.cypress-software.com/solutions/solutions.htm
Ferrarini, E. (February
4, 2002).
Three Storage Area Network Killer Apps. Retrieved February
24, 2002, from
http://www.enterprisestorageforum.com/sans/features/print/0,,10556_968101,00.html
Georgalas, N. (1998). A
Framework to Integrate Business Operational Data. Retreived
March 16, 2002, from http://www.labs.bt.com/people/georgan/UMIST98/UMISTwshop.htm
Goolsby, K (December, 2001). No Matter How You Slice It:
Data Warehousing Solution. Retrieved March 23, 2002 from http://www.teksouth.com/tradejournals.htm
Lawton, G. (February 2001). Knowledge
Management: Ready for Prime Time? Retrieved March 23,
2002 from http://dlib2.computer.org/co/books/co2001/pdf/r2012.pdf
Mullen, N. Information for Innovation: Developing an Enterprise Data Strategy. Retrieved March
16, 2002,
from http://www.accenture.com/xd/xd.asp?it=enWeb&xd=Services/se/se_data_strategy.xml&xt=print.xslt
Ortegon, G. (October 2001). Why Choose
NAS? Retrieved February 24, 2002, from http://www.storagesearch.com/fia-art1.html
Seligman, L. (April 4, 1996). A Metadata
Resource to Promote Data Integration. Retrieved March
7, 2002,
from http://www.computer.org/conferences/meta96/seligman/seligman.html
Skeogh (January, 2002). Data Reliability:
The Foundation for Successful Enterprise Applications. Retrieved March
16, 2002,
from http://www.delostechnology.com/WPaper/DelosWhitePaper-dwp020802.pdf
Van den Hoven, J. (2002). The Data
Warehouse: If You Build It with the Users, They Will Come. Enterprise Systems Integration, 2nd
Ed. (J. Myerson, Ed.). Auerbach Publications.
Virtualization (December 16, 2000). Retrieved February
24, 2002,
from http://searchstorage.techtarget.com/sDefinition/0,,sid5_gci499539,00.html
[Back to
Table of Contents]